

Apache Fluss vs. Apache Paimon: Two Engines for the Real-Time Lakehouse
If you’ve been tracking the evolution of real-time data architectures, you’ve probably heard the buzz around Apache Fluss (Incubating) and Apache Paimon. Both are...
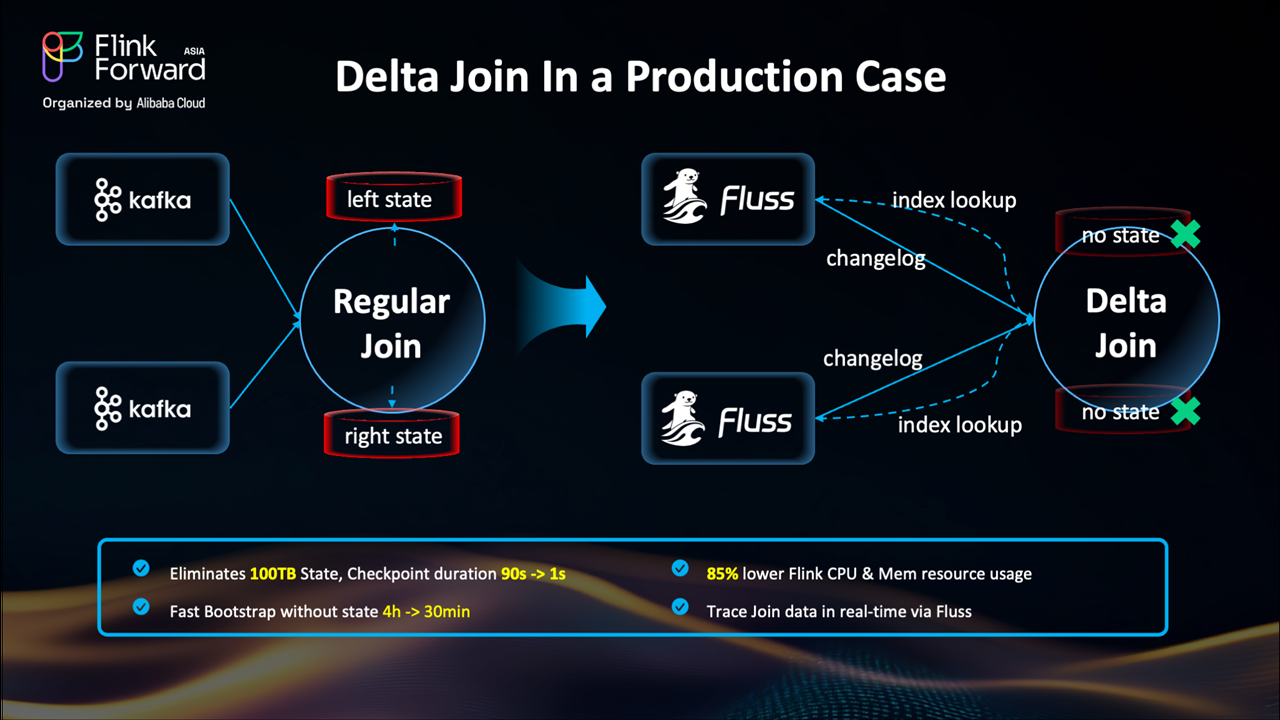
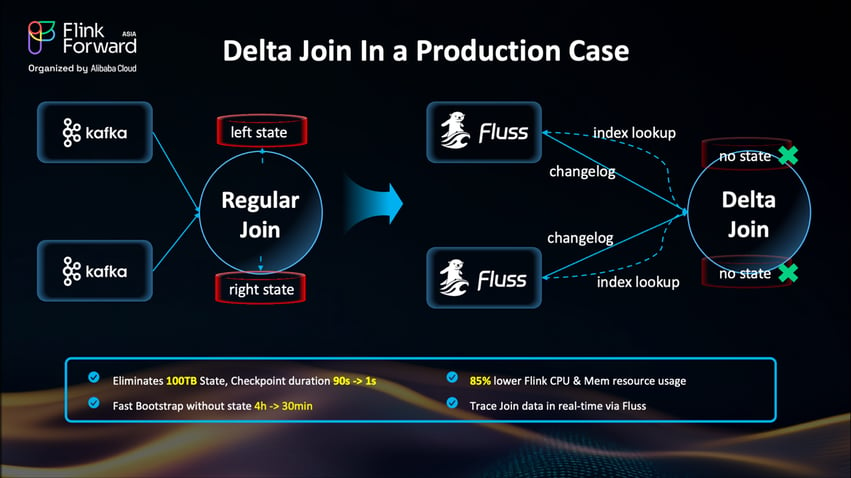
Apache Flink has always been great at stateful stream processing, but here's the thing: traditional stream joins hit a wall when dealing with massive amounts of data and high-cardinality keys. The problem? You need to keep all the historical data in Flink's state forever to ensure correctness, and that's just not sustainable.
Delta Join (FLIP-486) changes everything. Instead of buffering everything internally, it turns joins into a stateless lookup mechanism that directly queries data in tables like Apache Fluss or Apache Paimon.
Here's what Delta Join actually does: it separates compute from history. Instead of keeping everything in Flink's state, the operator just looks things up to external storage when needed. No more explosive state growth.
The numbers tell the story. Production deployments of Taobao team (Alibaba's ecommerce business) have seen:
This isn't just incremental improvement - it's a complete game changer for large-scale stream processing.
Regular Joins in Flink are incredibly flexible - they handle Insert, Update, Delete operations perfectly. But here's the catch: you have to keep ALL the history from both streams in Flink's state forever.
Since streaming jobs run indefinitely, that state just keeps growing. Forever. And in high-cardinality scenarios? That's a disaster waiting to happen.
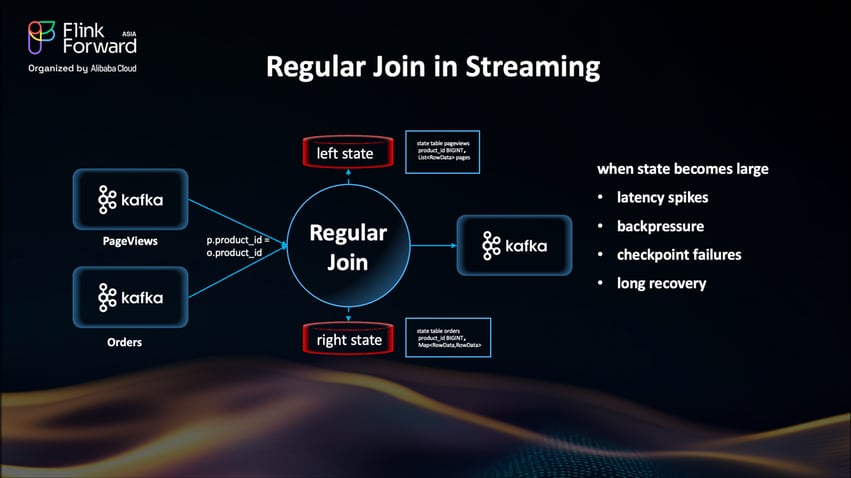
The problems pile up fast:
Before Delta Join, Flink had some limited options:
The core issue? Regular Joins forced Flink to duplicate data that was already stored elsewhere. It was like keeping copies of your database in memory just in case - inefficient and unsustainable.
Delta Join (FLIP-486) is all about separation of concerns. The principle is simple: "probe on demand, minimal job state, eventual consistency."
When an event hits either side of the join, the operator doesn't dig through internal history. Instead, it queries an external index in real-time. No more hoarding data - just look it up when you need it.
The StreamingDeltaJoinOperator is the engine that makes this all happen. Here's the key components:
Important: Delta Join isn't truly stateless - it's a hybrid model. The operator still keeps LRU caches and coordination state for consistency. The performance now depends on cache hit rates and external lookup latency.
Here's the tricky part: when you have parallel async lookups, you can get updates for the same key arriving out of order. That's bad news for correctness.
Delta Join uses FLIP-519's KeyedAsyncWaitOperator to solve this. It ensures that all operations for a single key happen in sequence, while different keys can still run in parallel. Smart approach - you get the throughput benefits without sacrificing correctness.
Apache Fluss (incubating) was built specifically for this use case. It's a disaggregated table storage engine designed from the ground up for Apache Flink.
Here's what makes it work:
customer_id instead of the full customer_id, order_id, item_id). Most systems require exact matches - Fluss is much more flexible.While Apache Fluss was the initial, purpose-built enabler for Delta Join, the Flink community recognizes the need to expand this concept to leverage open-source data lake formats. Continuous optimization of join performance remains a strategic focus. The roadmap for Flink SQL explicitly includes plans to add support for other storage systems, notably Apache Paimon, to facilitate near-real-time Delta Join capabilities.
Apache Paimon offers:
The goal: make Delta Join work across the entire Lakehouse ecosystem, not just Fluss.
The numbers don't lie - Delta Join delivers serious operational improvements.
Bonus: Since your join history lives in external storage, you can use it for other things too. One team reduced data reprocessing from 4 hours to 30 minutes by using Sort-Merge Joins on the externalized tables.
The best part? Delta Join works with standard SQL. No special syntax needed - just write your regular JOIN queries like SELECT * FROM orders INNER JOIN Product ON orders.productId = Product.id.
The optimizer is smart enough to automatically choose Delta Join when:
In recent Flink versions, this often happens automatically.
You can tune these parameters to optimize performance:
table.optimizer.delta-join.strategy='AUTO' - Let Flink decide whether a regular join can be converted to a delta join when applicable. Default is AUTO.table.exec.delta-join.cache-enabled='true' - Whether to enable the cache of delta join. Default is true.table.exec.delta-join.left.cache-size=10000 and table.exec.delta-join.right.cache-size=10000- The cache size used to cache the lookup results of the left and right table in delta join.table.exec.async-lookup.buffer-capacity=100 - The max number of async i/o operation that the delta join can trigger to lookupDelta Join shines in these scenarios:
Delta Join (FLIP-486) isn't just a new feature - it's a fundamental shift in how we think about stream processing at scale.
The trade-off is clear: instead of managing massive state within Flink's checkpoint domain, you pay the latency cost of external lookups. For enterprise-scale real-time applications, this is a no-brainer. You get:
Right now, it works great with specialized systems like Fluss (with those awesome prefix lookups). The future roadmap includes Apache Paimon and other Lakehouse formats, which means Delta Join will become a standard capability across the entire streaming ecosystem.
This is how Flink stays ahead as the go-to engine for large-scale, stateful stream processing.
A deep dive into Apache Flink 2.1’s SQL capabilities, focusing on real-time data processing and integration with AI workloads.
An in-depth case study from Alibaba showcasing how Taobao leverages Apache Fluss for scalable streaming storage and real-time analytics.