

The Delta Join in Apache Flink: Architectural Decoupling for Hyper-Scale Stream
The Paradigm Shift in Flink Stream Joins What Delta Join Solves Apache Flink has always been great at stateful stream processing, but here's the thing: traditional...
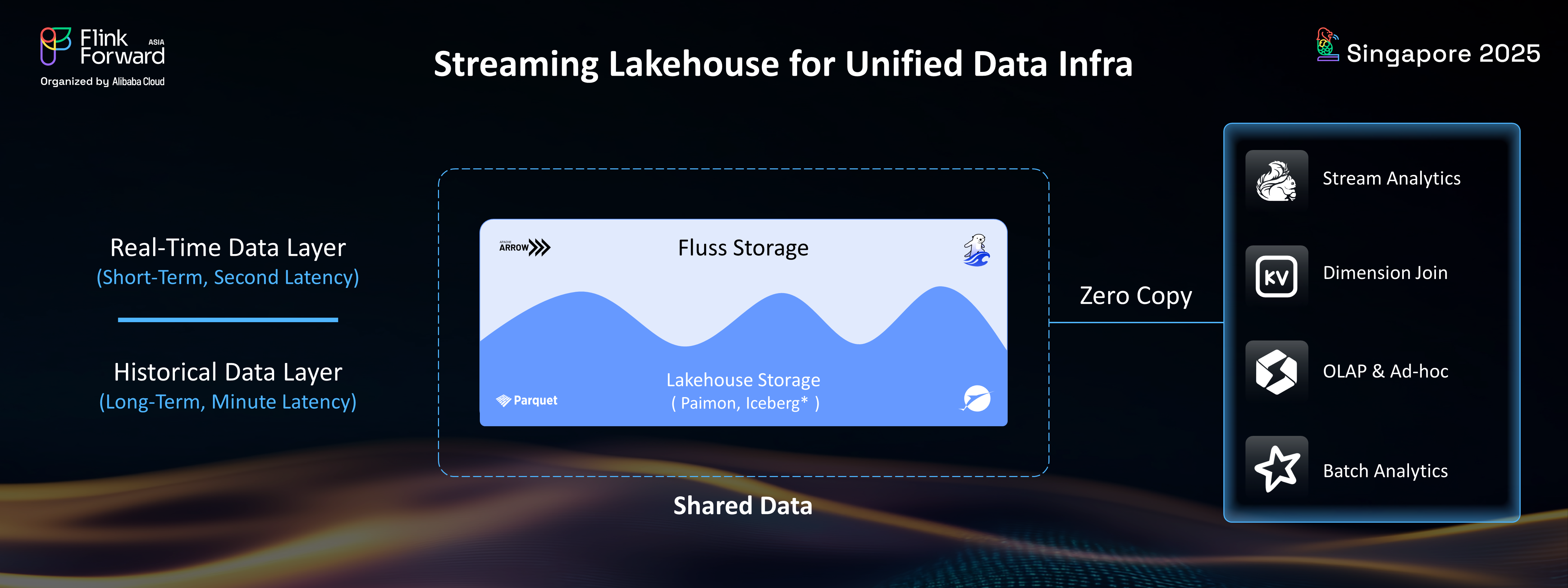
If you’ve been tracking the evolution of real-time data architectures, you’ve probably heard the buzz around Apache Fluss (Incubating) and Apache Paimon. Both are Apache/ Apache Incubator projects born from the Apache Flink community, and both aim to solve real pain points in building modern data platforms. But they’re not competitors—they’re more like teammates with very different jobs.
So, what’s the real difference? When should you use one over the other? And how do they fit into your lakehouse?
Let’s cut through the noise and break it down for engineers who actually build and run these systems.
learn more about Delta Join in articles below
Flink 2.1 SQL: Unlocking Real-time Data & AI Integration for Scalable Stream Processing
Together, they form a tiered Streamhouse: Fluss handles the “right now,” Paimon handles the “recent past + history.” You write once (into Fluss), and tier seamlessly to Paimon. Your apps query a unified view without knowing the difference.
Before diving in, let’s talk about the problem space.
Flink is amazing at processing streams, but it has two major pain points:
State explosion: Maintaining streaming joins in Flink state leads to massive checkpoints, slow recovery, and high memory usage.
Architectural fragmentation: You often end up with Kafka (for raw events), a database or cache (for low-latency lookups), and a data lake (for analytics)—three systems to manage, with data duplicated and inconsistent.

Both Fluss and Paimon aim to simplify this—but from opposite ends of the latency spectrum.
Paimon started life as Flink Table Store—a native storage engine for Flink dynamic tables. It’s now an Apache top-level project and functions as a streaming data lake format that natively supports streaming and batch.


changelog-producer = 'lookup'.Fluss (German for “river”) is a distributed, columnar streaming storage engine built for sub-second analytics. It’s not a message queue like Kafka—it’s an analytical store that looks like a queue but performs like a database.


Here’s where it gets powerful.
Imagine this flow:
user_events).This is called Union Read. To your query engine, it’s one table with second-level freshness and unlimited history.

No code changes. No data duplication. No consistency issues.
Fluss handles the “hot” path; Paimon handles the “warm + cold” path. And because both use aligned bucketing, the tiering is efficient and partition-aware.
Key insight: Fluss isn’t replacing Paimon—it’s accelerating it for the critical last few minutes of data.
Paimon is a drop-in upgrade for Delta/Iceberg if you’re all-in on Flink streaming. It’s mature, stable, and solves the “streaming lakehouse” problem elegantly.
This combo is for teams pushing the limits of real-time. If your SLA is “data must be queryable in <5 seconds,” Fluss is your answer.
Remember: Fluss is not a message queue. It’s a columnar streaming store that supports analytical workloads.
|
Capability |
Apache Fluss |
Apache Paimon |
|
Latency |
Sub-second (milliseconds to seconds) |
Minute-level (up to ~1 minute) |
|
Data Model |
Append-only (Log Tables), Primary Key (Update/Delete) |
Primary Key, Append, Bucketed Append, Partial Update |
|
Storage Format |
Native: Apache Arrow (IPC) |
Native: Parquet, ORC; Pluggable for future formats |
|
ACID Transactions |
read-your-writes consistency |
Yes, via two-phase commit and snapshot isolation |
|
Schema Evolution |
Not yet supported |
Yes, fully supported (add, remove columns) |
|
Time Travel |
Yes, via a tiered data lake table |
Yes, via immutable snapshots and tags |
|
Join Support |
Optimized for Lookup Joins via primary-key lookups and Delta Joins via index-key lookups |
Supports various merge engines for enrichment/aggregation |
|
Query Engines |
Primarily Flink; limited support beyond |
Broad ecosystem support: Spark, Trino, StarRocks, Hive, etc. |
|
Integration Focus |
Tiering to Paimon/Iceberg; Delta Join for Flink |
Native Flink/Spark connectors; Flink CDC integration |
The numbers speak for themselves:
These aren’t theoretical gains—they’re from production systems handling petabytes of data.
How Taobao uses Apache Fluss (Incubating) for Real-Time Processing in Search and RecSysBoth projects are moving fast:
Fluss is working on:
Paimon is adding:
The vision is clear: Fluss as the real-time front door, Paimon as the universal storage layer.
They’re not rivals—they’re designed to work together. Think of Fluss as the “cache” and Paimon as the “source of truth.” And thanks to Union Read, your apps don’t need to know the difference.
If you’re serious about real-time analytics at scale, this tiered Streamhouse architecture (Flink + Fluss + Paimon) is one of the most promising patterns we’ve seen in years. It reduces complexity, cuts costs, and delivers the latency that modern apps demand.
So evaluate both—but don’t see it as an either/or. See it as a stack.
Want to try it?
Prefer a no-setup, cloud-native experience? You can spin up a fully managed environment in minutes on Alibaba Cloud:
Both services are available in the Alibaba Cloud console—ideal for a quick test without managing infrastructure. Give it a shot and see the tiered Streamhouse in action!